uipath AI center
Document Understanding In AI center
AI Center는 Document Understanding Machine Learning 모델을 실행하는 infrastructure입니다.
Document Understanding Model과는 다음과 같은 단계가 연관 되어 있습니다.
- 문서 샘플과 추출해야하는 데이터 포인터의 요구 사항 수집
- Data Manager를 이용한 Data Labeling
- Labeling된 문서중 학습용을 골라내어 AI Center 저장소에 내보낸다.
- Labeling된 문서중 테스트용을 골라내어 AI Center 저장소에 내보낸다.
- AI Center에서 학습을 실행한다.
- 모델 성능을 평가 한다.
- 학습된 모델을 ML Skill로 AI center에 배포한다.
- RPA workflow에서 Document Understanding ML activity pack을 사용하여 ML skill을 이용한다.
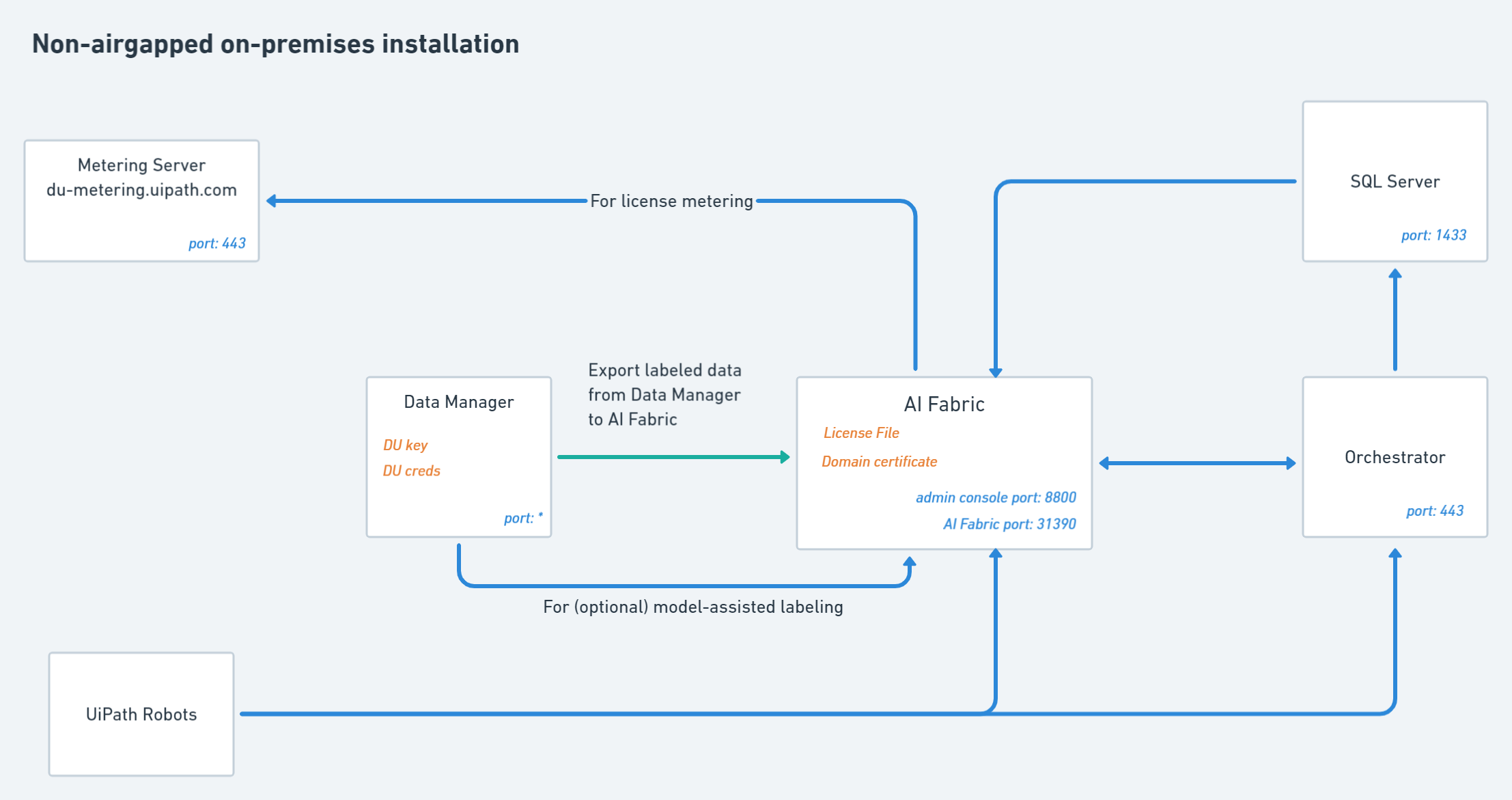
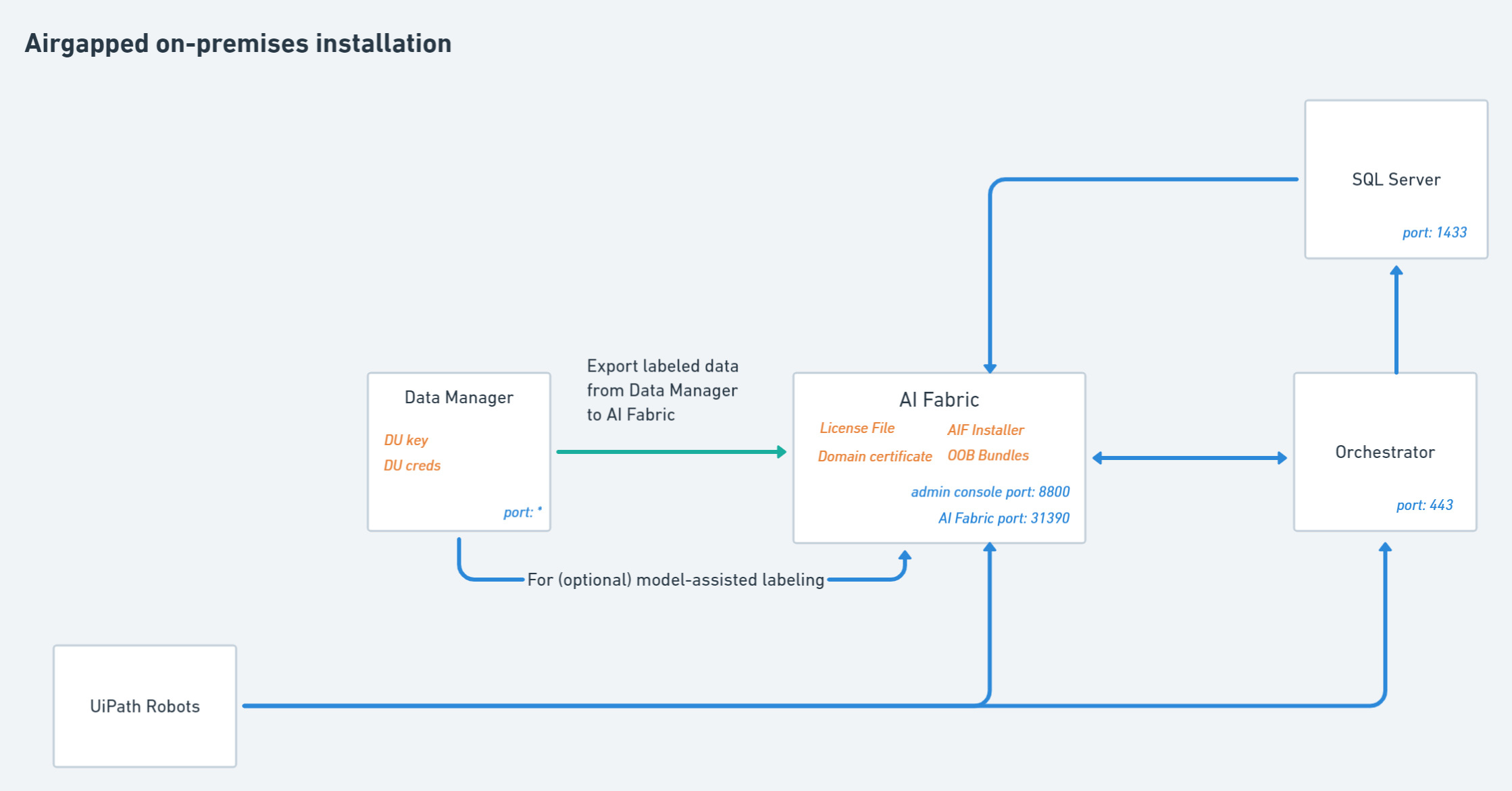
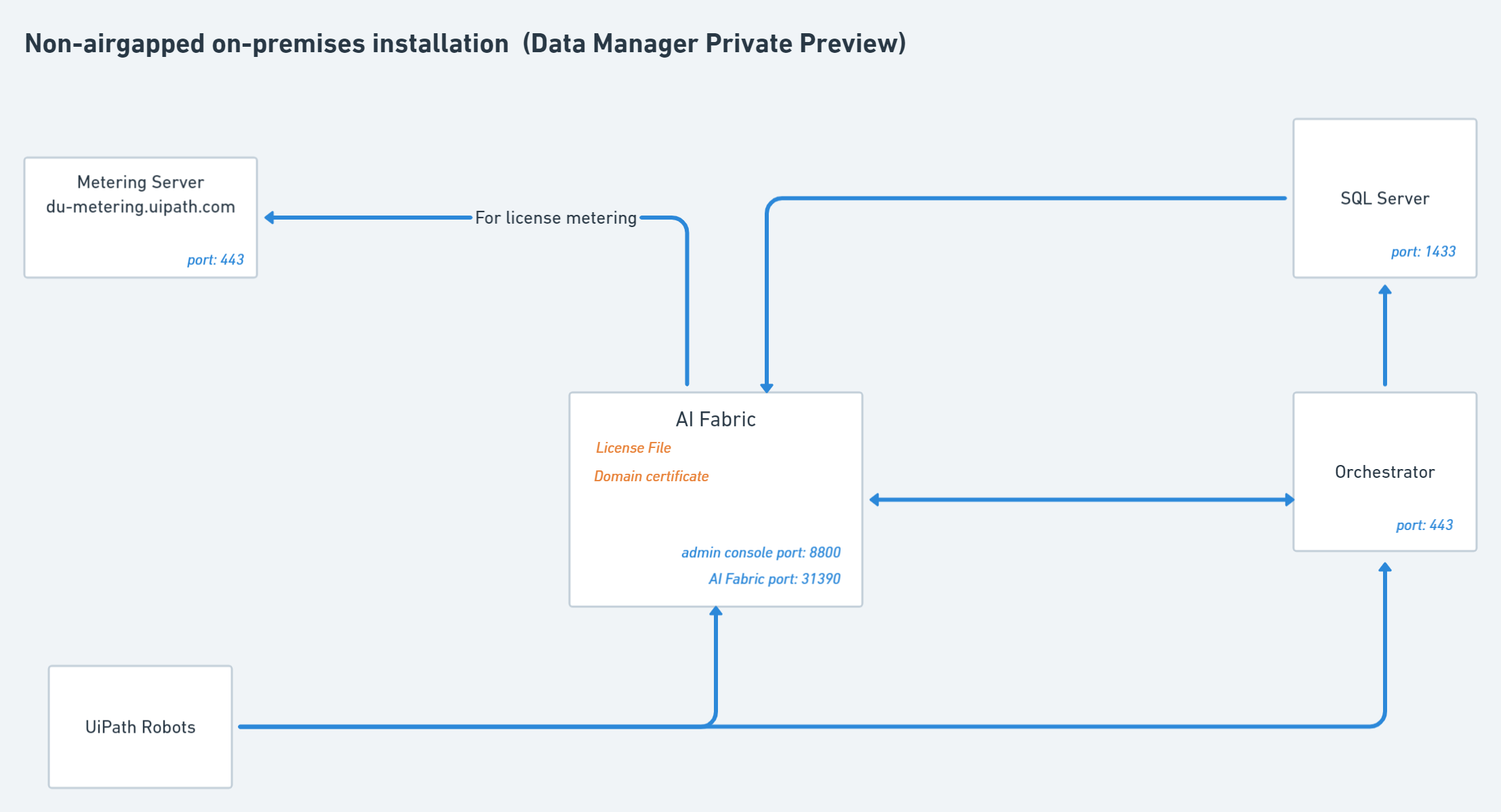
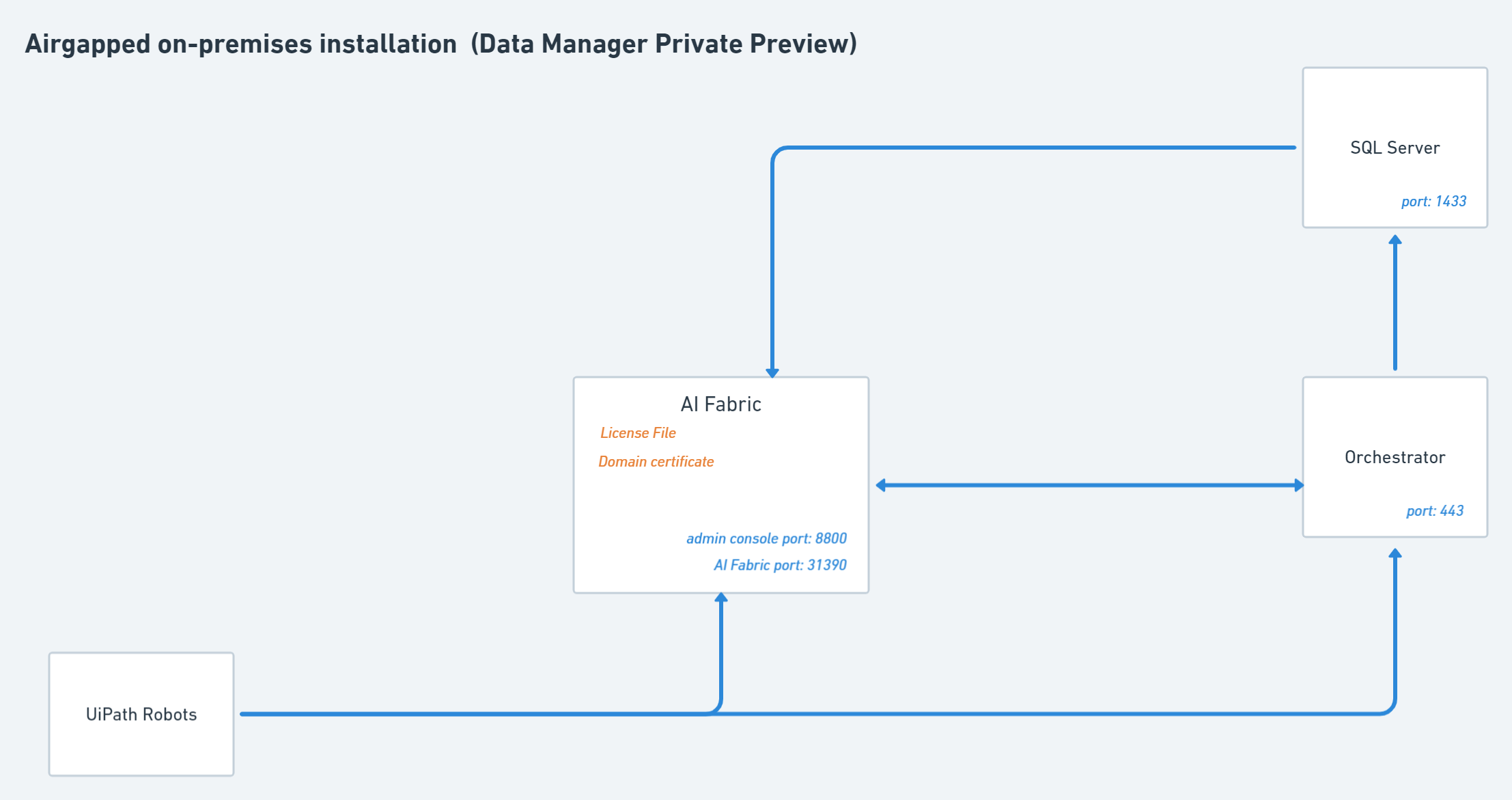
구성품
용어
- Ports : 서버 포트번호
- 파란 화살표 : network통신, 화살표가 나온 곳이 요청 하는 곳
- 초록 화살표 : user action
- DU key : uipath.cloud.com 에서 받은 document understanding key
- DU creds : Account Executive 로 부터 받은 사용자 계정
- License File : 진짜 라이센스 파일, YAML형태인듯
- Domain Certificate : Ai Fabric 은 신뢰할 수 있는 인증기관에서 받은 인증서가 필요합니다.
- AIF installer : download.uipath.com에서 받은 tar file(air gapped에 필요)
- OOB bundles : ML 모델을 다운 받을 수 있는 URL? account Executive한테 연락해보란다.(air gapped에 필요)
Data Manager
Data Manager 설치
https://docs.uipath.com/document-understanding/docs/install-data-manager
궁금하면 찾아보자 일단 스킵!
Configure Data Manager
여기에 스키마가 있다 스키마 받아서 써야 학습이된다. https://docs.uipath.com/document-understanding/docs/configure-data-manager
궁금하면 찾아보자 일단 스킵!
Configure OCR
문서 이미지를 DataManager에 가져오기 위해서는 OCR 설정은 필수입니다.
또한 배포할떄의 OCR과 학습할때의 OCR을 반드시 동일한 엔진으로 사용해야합니다.
Configure Prelabeling
이미 라벨링 할 수 있도록 필드들을 뽑아놓은 모델이 있을때 씁니다. Prelabeling을 쓰면 시간이 대폭 줄어듭니다. 또한 URL을 제공하는 ML model이어야 합니다.
Using Data Manager
import Documents
파일명에 특수문자 사용 불가 영문, 숫자, dash(-), under score(_)만 가능
import는 다음과 같이 여러 방법이 있습니다.
- Schema import
- Raw documents import
- Data Manager Dataset import
- Machine Learning Extractor Trainer dataset import (preview 기능)
schema import (DataManager dataset import랑 무슨차이?)
이미 존재하는 data manager의 인스턴스와 같은 스키마를 새로운 인스턴스에서도 사용하려면 다음 절차를 따르면 됩니다.
- 새로운 인스턴스를 생성합니다.
- 이미 존재하는 인스턴스에서 레이블 데이터를 export 합니다.
- zip파일을 압축풀지말고 업로드 합니다.
Raw document import
labeling에 지원하는 문서 종류는 .pdf, .tiff, .png, .jpg 파일입니다.
- import 버튼을 클릭합니다.
- Batch Name을 지어줍니다.
- 학습용이면 ‘Make this a test set’체크 박스를 해제합니다.
- 테스트용이면 ‘Make this a test set’체크 박스를 체크합니다.
- 지원하는 파일을 업로드 합니다. zip파일도 가능합니다.
Validation Station dataset import (미리보기 기능)
프로세스 실행중 Data Extractino -> Human Validation을 거친 데이터를 다시 재학습 시킬 수 있습니다.
재학습은 자동으로 이루어 지는 것이 아니라. Machine Learning Extractor Trainer로 생성된 OutputFolder를 다시 Data Manager로 입력해 주어야 합니다.
과정은 다음과 같습니다.
- ML Extractor Trainer가 생성한 폴더의 구성 : documents, metadata, predictions
- 이 output 폴더를 zip파일로 압축합니다.
- Data Manager에 zip파일을 import합니다.
- 레이블링을 확인하고 다시 export합니다.
- pipeline을통해 학습을 실행합니다.
Adding and Configuration Fields
Feild는 삭제나 수정이 불가능 하기 때문에 신중하게 설정해야 합니다. 다만 ML 모델에서 사용안할 feild는 숨김 처리 할 수 있습니다. 최대 40개 필드 까지 설정 가능합니다
Colum Feild
예를 들자면 invoice에서 Description이나 Unit Price가 있습니다.
Regular Feild
문서에서 단 한번만 등장하는 부분입니다. 예를 들자면 invoice에서 invoice number, Total amount와 같습니다.
Classifier Feild
문서의 종류를 구분하는 필드입니다. 영수증에서 (음식, 호텔, 항공, 운수…) 옥은 invoice에서 화폐(USD, EUR, JPY)등이 있습니다.
Label Documents
문서안에 필요 없는 페이지들은 data manager에서 delete해야 합니다. 혹은 원하는 필드가 1~2개인 경우도 delete해야 합니다.
라벨링 작업을 하는 training 데이터들은 균형이 있어야 합니다. 예를 들면 영수증 학습을 시키는데 어느 회사껀 1000장 어느회사껀 10장 이런 식의 데이터는 피해야 합니다. 보통 한 layout에 2-3종류의 문서면 충분합니다.
Feilds that occur multiple times on the same document
문서에 같은 문자가 여러번 등장할떄 그것이 같은 것을 의미하면 모두 labeling을 해야합니다.
AI center
About Project
프로젝트는 비즈니스의 단위이다.
About Datasets
기계학습의 모델이 학습에 참고할 데이터 모음
About ML Package
ML 패키지는 기계 학습 모델을 교육하고 제공하는 데 필요한 모든 코드와 메타 데이터가 포함 된 폴더입니다.
building package
python등으로 작성한 ML model을 코드 조금 수정하여 ML Package로 사용할 수 있습니다.
즉시 사용 가능한 package (out of box package)
Uipath는 즉시 사용가능한 ai package를 많이 만들어 놨습니다. 또한 오픈소스로 개발중인 패키지도 사용 할 수있습니다.
Uipath Document Understanding packages
Document understanding package도 종류가 있습니다.
- Document Understanding : 처음부터 학습 시켜야 하는 모델
- Out of the box Pre-trained models : 미리 학습 시켰지만 커스터마이징 해서 다시 학습시킬수 있는 모델
- invoice : https://du.uipath.com/ie/invoices/info/model
- Receipt : https://du.uipath.com/ie/receipts/info/model
- Purchase Orders : https://du.uipath.com/ie/purchase_orders/info/model
- Utility Bills : https://du.uipath.com/ie/utility_bills/info/model
- invoice india : https://du.uipath.com/ie/invoices_india/info/model
- invoice austrailia : https://du.uipath.com/ie/invoices_au/info/model
Models Details
- input type : file (pdf, png, bmp, jpeg, tiff)
- input description : 파일은 digitiezed가 완료되어야 하며, input 은 Data Extraction Scope 안에서 해야 합니다.
- output description : ML model에서 모든 feild가 추출된 json 파일, Data Extraction Scope에서 설정되며, ExtractionResult 변수에 담깁니다. Export Extraction Result activity에서 Dataset으로 변경 가능합니다.
pipeline
두종류의 학습 pieline이 있습니다.
- Document Understanding
- 다양성이 적은 문서는 30 ~ 50 개 문서만 학습 시켜도 좋은 결과를 얻습니다. 다양성이 큰 문서는 regular 필드당 20 ~ 50개의 문서를 학습시켜야 합니다.따라서 10개의 필드면 200~500개가 있어야 합니다. 컬럼 필드를 학습 시키려면 컬럼당 50 ~ 200개 데이터를 학습시켜야 합니다. 다양성이 적은 문서면 5개의 컬럼에 대해 300 ~ 400개의 데이터가 필요합니다. 하지만 다양성이 크다면 1000개는 필요합니다.
- Invoices, Receipts, Purchase Orders, Utility Bills, Invoices India or Invoices Australia.
- 이미 존재하는 필드를 정확도를 높이기 위해 학습 시킨다면 100 ~ 500개 문서가 필요합니다. 새로운 필드는 30 ~ 50 개면 됩니다. Classification 필드는 재학습이 불가능합니다.
Training on GPU or on CPU
GPU를 이용하는게 CPU보다 학습이 10배는 빠릅니다. 게다가 CPU는 최대 500개 이미지만 학습 가능합니다.
Dataset Format
Data Manager에서 export된 폴더는 다음과 같이 구성됩니다.
- images : 레이블된 이미지를 담아두는 폴더
- lates : 각 페이지별 레이블링 데이터가 기록된 json 파일을 담아두는 폴더
- schema.json : 추출해야할 필드들의 와 필드의 데이터 타입을 담고있는 파일
- split.csv : 학습데이터 와 검증데이터를 구분하는 정보를 담고 있는 파일
Artifacts
pipeline이 Full 이나 Evaluation일때 output으로 “artifacts”폴더가 생성됩니다. 그 구성은 다음과 같습니다.
- evaluation_metrics.txt 파일은 예측된 필드의 F1점수를 담습니다. line items는 모든 컬럼의 global score만 담습니다.
- evaluation.xlsx는 모델에 의해 예측된 각 필드에 대한 예측값과 실제 값을 비교 하는 excel입니다. 따라서 진단 및 문제 해결을 위해 가장 부정확한 문서가 맨 위에 표시됩니다.
about pipelines
파이프라인은 기계학습 워크플로우에 대한 설명입니다. 파이프라인은 입출력이 존재합니다.
pipeline status
- scheduled : 진짜 스케줄된 상태
- packaging : 실행하기 위해 도커 이미지를 만드는 단계,처음 학습 하는 경우 20분씩 걸린다.
- waiting for resources : 사용 가능한 라이센스를 탐색합니다. 매 5분 마다 새로 탐색합니다.
- Running : pipeline 실행 시작하여 진행중이다.
- Failed : 실행 중 실패
- killed :
reference : https://docs.uipath.com/document-understanding/docs/ai-center-relation-to-du
reference : https://docs.uipath.com/ai-fabric/v0/docs/about-ai-center
reference : https://docs.uipath.com/ai-fabric/docs/ml-packages-examples