uipath Document Understanding
시작하기
소개
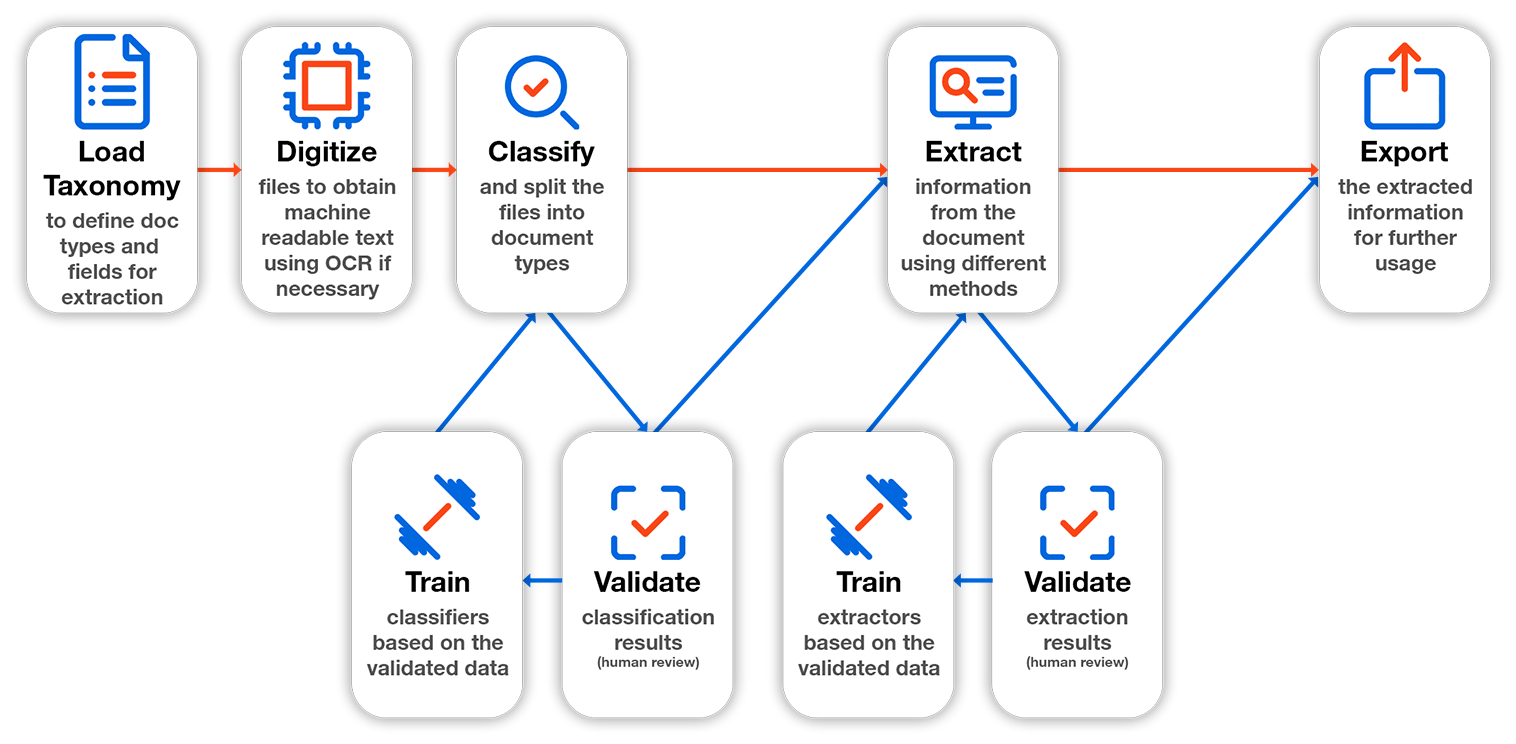
Document Understanding은 단 하나의 워크플로우로 다양한 형태의 문서에서 데이터를 추출하는데 목적이 있습니다.
Document Understanding Framework 구성:
- Taxonomy : 어떤 문서를 처리해야하며 어떤 데이터가 필요합니까? 문서의 유형과 추출할 데이터에 대한 정보를 정의합니다.
- Digitization : 이 문서에는 뭐가 들어있나요? 문서가 가지고 있는 문자(기계가 읽을 수 있는)를 얻습니다.
- Document Classification : 이 파일에서 분류를 통해 어떤 유형의 문서를 찾았습니까? digitized된 파일의 문서 유형을 자동으로 정합니다.
- Document Classification Validation : 예측한 문서 분류가 맞나요? 사람이 검토하고 수정할 수 있는 방법입니다.
- Classification training : 사람이 데이터를 검토 했나요? 로봇이 사람의 검토를 통해 학습합니다. 인간의 검증 데이터를 다시 분류기에 입력하므로써 로봇의 예측 능력을 향상시킵니다.
- Data Extraction : 특정 문서에 무슨 데이터가 있나요?
- Data Extraction validation : 추출한 데이터가 맞나요? 사람이 검토하고 수정할 수 있는 방법입니다.
- Data Extraction training : 사람이 데이터를 검토 했나요? 검토한 데이터를 통해 로봇이 다시 학습합니다.
- Data Consumtion : 데이터를 사용하기 위해 내보냅니다.
위 구성들을 사용하려면 Uipath.IntelligentOCR.Activities 패키지를 설치 해야 하며, 설치하면 studio 리본 메뉴에 Taxonomy Manager 버튼이 생깁니다.
Scope 액티비티들은 (Classify Document Scope, Data Extraction Scope, Train Classifiers Scope, Train Extractors Scope) documnet understanding framework 구성을 사용하는데 개별 상황에 맞춰 내부적으로 다른 알고리즘들을 사용하도록 허용합니다.
Document Understanding Framework는 custom 분류기와 추출기를 사용할 수 있습니다. 이것들은 Uipath.DocumentProcessing.Contracts 패키지의 추상 클래스를 상속하여 생성할 수 있습니다. Custom OCR engine 또한 Uipath.OCR.Activities의 추상클래스를 상속하여 생성할 수 있습니다.
Framework Components
Taxonomy
Taxonomy 개요
Taxonomy는 Document Understandin Framework의 각 스텝마다 고려하는 metadata입니다.
Taxonomy는 Document Type들의 모임입니다.
Document Type은 문서의 논리적인 문서 유형의 정의 이며, 각기 다른 비즈니스 프로세스에서 처리됩니다. 예를 들면 invoice, 계약서, 주문서 등등..Document Type은 field들의 모임을 가지고 있습니다.
field는 특정 문서 유형에 존재 하는 것으로 예상 되는 정보입니다.
field를 통해 데이터를 추출합니다.
Taxonomy 만들고 사용하기
Uipath.IntelligentOCR.Activities를 설치하면 Studio의 리본메뉴에 Taxonomy Manager 버튼이 등장합니다. 그 버튼을 눌러서 Taxonomy를 편집합니다. Taxonomy 메타데이터는 Uipath 프로젝트 폴더에 생성된 DocumentProcessing 폴더 아래에 taxonomy.json으로 생성됩니다. 이 파일은 프로젝트 마다 고유하게 존재하며, 다른 프로젝트에서 재사용하고 싶을때는 단순히 복사 붙여넣기를 하면 됩니다.
Taxonomy manager
문서 유형을 정하기 전에 그룹과 카테고리라는 계층 구조를 먼저 고민해야합니다.
Digitization
Digitization 개요
이미지로 부터 기계가 읽을 수 있는 문자들을 얻는 작업입니다.
Digitization은 두가지 output이 있습니다.
- 문서로 부터 추출한 Text, String 자료형에 저장됩니다.
- Document Object Model 문서에 관한 정보(이름, 내용, text 길이, 페이지수, 문서 회전각도, 글자의 위치..)를 답고 있는 json object 입니다.
Digitization을 하면 안돼는 것
OCR과 연관이 있지만 Digitization은 OCR이 아닙니다. 특히 이미 기계가 읽을 수 있는 양식인 native pdf 파일은 OCR을 하지 않아도 됩니다.
Dizitization에 OCR을 이용해야 할 떄
- 이미지 파일들
- .png, .gif, .jpe, .jpg, .jpeg, .tiff, .tif, .bmp
- 여러 페이지의 tiff 파일은 각 페이지마다 ocr을 실행해야 합니다.
- PDF 문서들
- machine readable content가 없는 pdf 문서
- 이미지가 아주 큰 영역을 차지하는 pdf 문서
ForceAppliOCR 옵션은 파일의 상당 부분의 native content가 포함되어 있는 것처럼 보이지만 사용자가 봤을 때는 그 내용이 다를 때 사용합니다.
Document Classification
Document Classification 개요
로봇이 작업을 수행하는데 어떤 유형의 문서인지 식별하기 위해 사용합니다.
결과는 ClassificatinResults의 배열 형태인데, 입력 파일에 페이지가 여러개 있는경우 각각에 대해 Classification을 수행합니다.
Document Classification을 해야할 때
처리해야할 문서의 종류가 하나이고 그 형태 또한 고정되어있다면 이것을 할 필요가 없습니다.
그러나 처리해야할 문서의 종류도 여러가지이며 한 파일에 여러 종류의 문서가 있다면 반드시 Document Classification을 해야만합니다.
Document Classification 사용하는 법
- 모든 분류자 알고리즘이 사용할 구성 설정을 합니다.
- 한개 이상의 분류자를 사용합니다.
- 문서 유혈 필터링, taxonomy 매핑, 최소 신뢰도 임계값을 설정합니다.
- 분류 정보를 보고합니다.
분류자 구성 설정
- 어떤 문서 유형을 어떤 분류자가 분류할지,
- 각 분류기에 대한 최소 신뢰 임계값
Classify Document Scope에서 Classifier의 순서는 아주 중요합니다.
- classifier는 왼쪽에서 오른쪽으로 실행 합니다.
- classifier는 분류한 문서의 최소 신뢰값 이상인 경우에만 결과를 반환합니다.
- classifier는 이전 분류자에 의햇 분류되지 않은 페이지 범위로 실행합니다.
Classify Document Scope 구성 설정
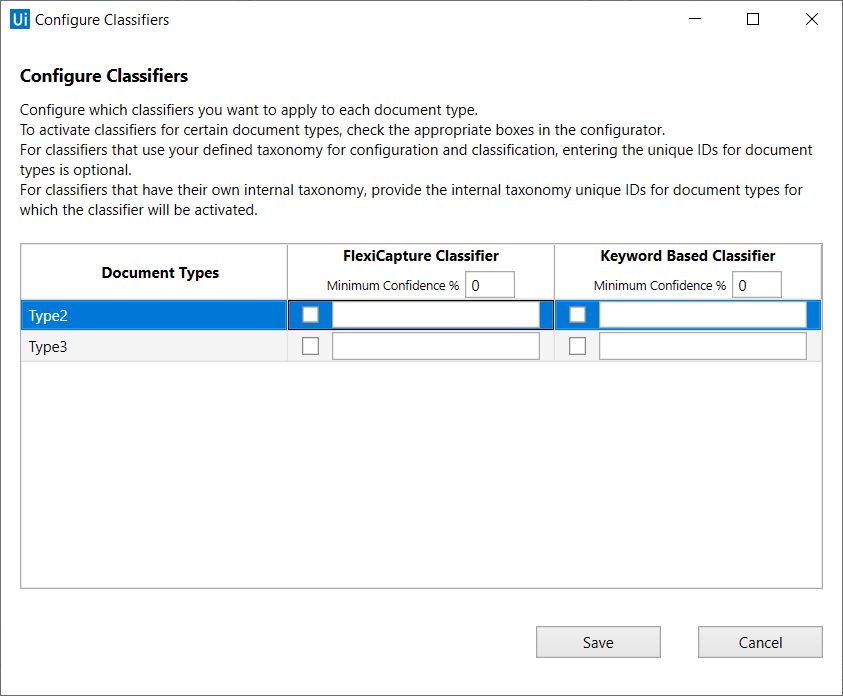
Document Type을 체크 하지 않는 경우는
- 분류기가 해당 Document Type을 학습하지 않은경우
- 분류기가 해당 Document Type에 대해 예상대로 수행하지 않는 경우
분류결과가 최소 신뢰 임계값 보다 작으면 Classify Document Scope는 그 결과를 무시합니다.
Keyword base Classifier
Keyword base Classifier의 알고리즘은 문서 제목이 같을 경우 그 문서 유형도 같다는 전제하에 시작합니다.
학습파일 경로는 변수로 바인딩 불가
문서 분류 과정
- taxonomy 분류 유형의 학습데이터에서 가장 일치하는 문자열을 찾습니다.
- 신뢰도 계산 기준
- 문서의 시작부분과 얼마나 일치 하는가
언제 사용하는가?
- 파일이 하나의 문서유형만 있을때
- 파일의 앞 3페이지에서 파일 유형에 관한 단서가 있을 때
Intelligent Keyword Classifier
Intelligent Keyword Classifier의 알고리즘은 한 문서안의 반복되는 내용을 중심으로 구축되었습니다. 동일한 문서 유형에서 일반적으로 발생하는 일련의 단어가 있으므로 벡터 유사성 계산이 가능하다는 전제에서 시작합니다.
학습파일 경로는 변수로 바인딩 불가
문서 분류 과정
- 문서와 가장 가까운 단어 벡터를 찾습니다.
- 가장 높은 점수를 받은 문서유형을 보고 합니다.
Intelligent Keyword Classifier는 file splitting 능력이 있습니다. 따라서 파일의 페이지마다 다른 문서 유형을 결과로 반환할 수 있습니다.
언제 사용하는가?
- 한 파일에 여러 문서 유형이 있을 때
- 문서 유형은 같으나 내용에 따라 구성이 쉽게 변하는 경우
Special Requirements
Automation cloud의 api키를 이용하거나 on-prem일 경우 AI center의 Intelligent Keyword classifier를 따로 호스팅해야 합니다.
Document Classification Validation
Document Classification Validation이란?
문서 유형 분류 후에 사람의 검증 작업을 옵션으로 진행 할 수 있습니다.(uipath에서 사용하도록 적극 권장)
검증작업을 사용한다면, 그 다음 작업은 모두 올바른 분류 정보를 이용할 수 있습니다.
언제 사용하는가?
- 100% 정확해야 하는 업무일때
- 한 파일에 여러 문서 유형이 있을 때, 후에 DataExtraction을 진핼할 때 사용합니다. 서로 다른 문서유형의 dataExtraction을 피하기 위해서
어떻게 사용하는가?
- Attended인경우 Present Classification Station 액티비티 사용
- Orchestrator Action Center를 이용하는 경우, Create Document Classifcation Action과 Wait for Document Classification Action And Resume 액티비티 사용
Wait for Document Classification Action And Resume에서는 출력으로 “액션개체”와 “유효성이 검사된 분류 결과”만 있으면 됨
Classification Station
Classification Station wizard Orchestrator나 Stand-alone attended 모두 사용가능합니다.
Requirements of Classification Station
아래 나열된 input은 필수입니다.
- Taxonomy : LoadTaxonomy로 생성된 변수
- Document path : 문서 이미지 경로
- Document Object Model : Digitize Document 결과가 저장된 변수
- Document Text : OCR을 실행한 결과 Text
- Automatic Classifcation Result : 문서 유형 분류 결과가 저장된 변수
Document Classification Training
Document Classification Training 개요
언제 사용하는가?
인간의 검증작업을 통해 로봇이 학습하고 더 좋은 결과를 낼 수 있습니다. Document Understanding Framework에 Traing 구성요소는 선택사항입니다. 다음과 같은 경우는
- 분류기가 학습기능을 지원하지 않을때
- 단지 사용자가 학습 기능을 사용하고 싶지 않을때
- 학습 프로세스를 실행 프로세스와 분류하여 사용할때
하지만 Uipath에서는 self-learning algorithm을 사용할 것을 적극권장합니다.
어떻게 사용하는가?
Training은 반드시 사람의 feedback만 받습니다. 따라서 validation 작업 이후에 수행합니다. 실패한 분류, 성공한 분류 모두 가치있는 학습데이터입니다. Document Classify 단계에서 사용하지 않았던 분류기라도 나중에 사용하기 위해 학습을 시켜놓을 수 있습니다. 예외는 학습 불가
Uipath에서 제공하는 Trainer는 Keyword based Classifier Trainer, Intelligent Keyword Classifier Trainer 두가지 입니다.
Wait for Document Classification Action And Resume의 출력으로는 Validated Classification Results만으로도 충분
Data Extraction
Data Extraction 개요
문서에서 원하는 데이터만 추출할 수 있는 기능입니다. Taxonomy Manger로 지정한 Field만 데이터를 추출할 수 있습니다. 만약 한 파일안에 여러 종류의 문서가 있다면 각 문서 종류마다 Data Extraction이 한번씩 실행 됩니다.
어떻게 쓰는가?
- 추출기 구성 설정을 한다.
- 한개 이상의 추출기를 사용한다.
Data Extraction Scope로 설정할 수 있는 것들
- 각 추출기가 어떤 필드를 추출하는지
- 각 추출기의 최소 신뢰도 지정
- 각 필드마다 다른 추출기 지정가능
- 설정한 신뢰도 이하의 결과인 경우 다음 추출기가 해당 필드의 데이터 추출
- 추출기는 왼쪽 부터 실행
사용가능한 추출기
- Regex Based Extractor
- Form Extractor
- Intelligent Form Extractor
- Machine Learning Extractor
RegEx Based Extractor
추출할 데이터가 항상 그자리 같은 형식인 경우 사용, 그러나 절대 비추한다. 심지어 Training도 할 수 없음
Form Extractor
하나의 문서 유형에서 문서 구성(Layout)이 바뀌지 않을때 사용합니다. 따라서 하나의 템플릿을 기반으로 그와 동일한 방식의 문서들만 데이터를 추출할 수 있습니다.(이미지의 픽셀을 이용하여 추출)
다음과 같은 경우 다른 추출기를 사용하는 것이 좋습니다.
- 문서의 Layout이 아주 다양한 경우 (3,4개 이상)
- 문서마다 사이즈, 기울기등 세세한 부분에서 차이가 많이 나는 경우
Intelligent Form Extractor
이건 기본적으로 Form Extractor를 기본으로 만들어진 추출기 이다.
다만 아래와 같은 기능이 추가 되있을뿐…
- 손글씨 데이터 추출
- signature detection
쓸일이 있을까 싶다.
Machine Learning Extractor
하나의 문서 유형에 여러가지 Layout이 존재할 때 반드시 사용합니다.
이미지 픽셀이 50X50 이하인 경우 에러 발생
Special Requirements
- 데이터 추출을 위한 uipath document understanding endpoint
- Automation Cloud AI center에 올라와 있는 AI 모델 필요
- on-prem으로 호스팅 중인 AI center에 있는 AI모델을 쓸수 있지만 그래도 API키는 Automation Cloud에 있는것을 써야함
설정 방법
설정 전에 AI Center에 대해 보고 오세요
activity 설정
Endpoint혹은 ML스킬 둘중에 하나만 써야한다.
Validation Station
100% 정확한 데이터를 원할떄 validation을 합니다. vaildation을 꼭 하기를 추천합니다. 문서 분류와 마찬가지로 추출데이터도 사람의 검증을 거칠 수 있습니다. Stand-alone Attended, Orchestrator/Action center 모두 사용가능합니다.
- attended : Present Validation Scope
- Orchestrator/Action center : Create Document Validation Action, Wait for Document Validation Action and Resume
Requirements for Document Validation
validation을 위해서는 다음과 같은 데이터가 필요합니다.
- Taxonomy : taxonomy 단계에서 생성된 변수
- Document Path : 문서 이미지 경로
- Document Object Model : Digitization에서 생성된 변수
- Document Text : Digitization에서 생성된 변수
- Automation Extraction Result : Extract를 거쳐서 생성된 추출데이터
Data Extraction Training
When Data Extraction Training Should Be Used
다음의 경우를 제외하고는 재학습 시켜야 합니다.
- Extractor(ML Package)가 retraining을 지원하지 않을 때.
- 처리데이터를 재학습 시키고 싶지 않을떄(?? 즉 재학습은 선택사항이다.)
- 재학습을 문서 처리과정 중에 하는 것이 아니라 따로 하고싶을 때
How to Use the Data Extraction Training Component
여러 extractor를 사용할때 trainer도 여러개 쓸수 있습니다. Human Validation 이후에 사용해야합니다.
Data Extraction Scope에서 사용한 Extractor건, 사용하지 않았건, 모두다 재학습 가능합니다.
Train Extractor가 하는 일
- Trainer가 필요한 구성요소 제공
- 한개 이상의 trainer 수용
- 문서 타입과 필드 수준의 필터링, extractor 내부에서 이루어진 taxonomy와 project 수준에서 이루어진 taxonomy 매핑
Train Extractor scope로 커스터마이징 가능한것들
- 어떤 문서 유형과 필드를 train할것인지
- 프로젝트 수준에서 이루어진 문서 유형 분류와 extractor 내부에서 이루어진 문서 유형 분류의 매핑
refernece : https://docs.uipath.com/document-understanding/docs/introduction