R을 이용하여 영화 추천해보고, 취향이 비슷한 사람끼리 군집화 해보기
설문조사 하기
데이터마이닝 수강생을 상대로 선호 영화를 조사 했습니다. 수강생중에서 15명이 응답을 해주었고 설문 내용은 영화 14개를 임의로 선정하여 좋다 혹은 싫다를 고르도록 했습니다.
- 원령공주
- 인셉션
- 지구를 지켜라
- 태극기 휘날리며
- 달콤한 인생
- 올드보이
- 라이언 일병 구하기
- 이웃짐 토토로
- 너의 이름은
- 에반 게리온
- 센과 치히로의 행방 불명
- 타이타닉
- 트루먼 쇼
- 아이엠 샘
데이터 가공하기
설정
setwd('~/Documents/lectures/DM/Recommend/')
watch.movies.matrix<-read.csv("movieReserch.csv")
제가 데이터 파일을 저장한 경로와 데이터를 읽는 과정입니다. 설문 결과 다음과 같이 얻어진 데이터를
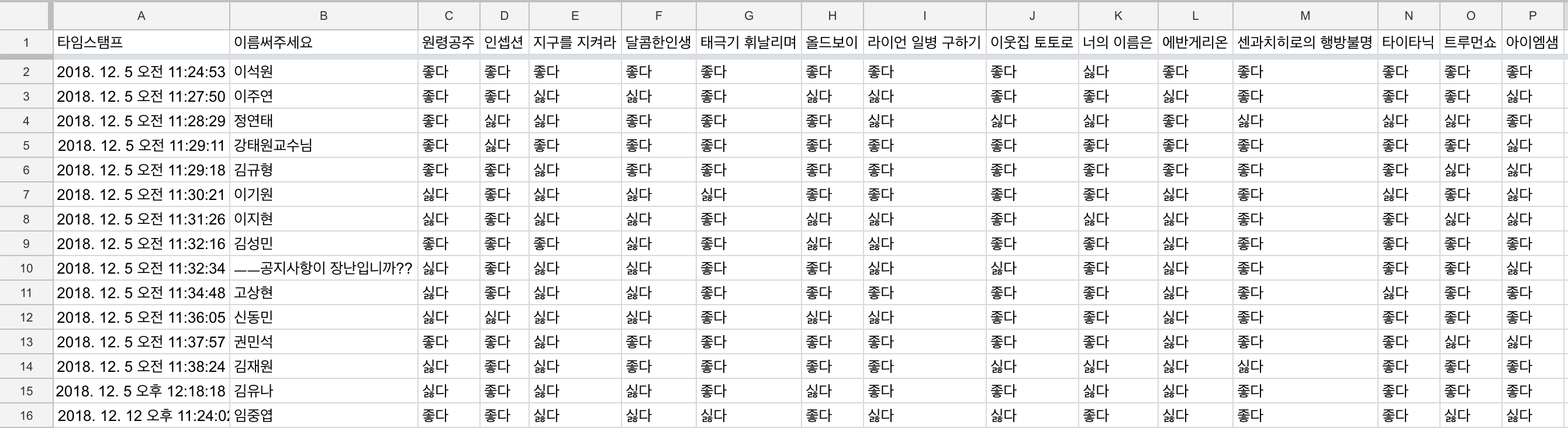
다음과 같이 변경하고 .csv파일로 저장 했습니다.
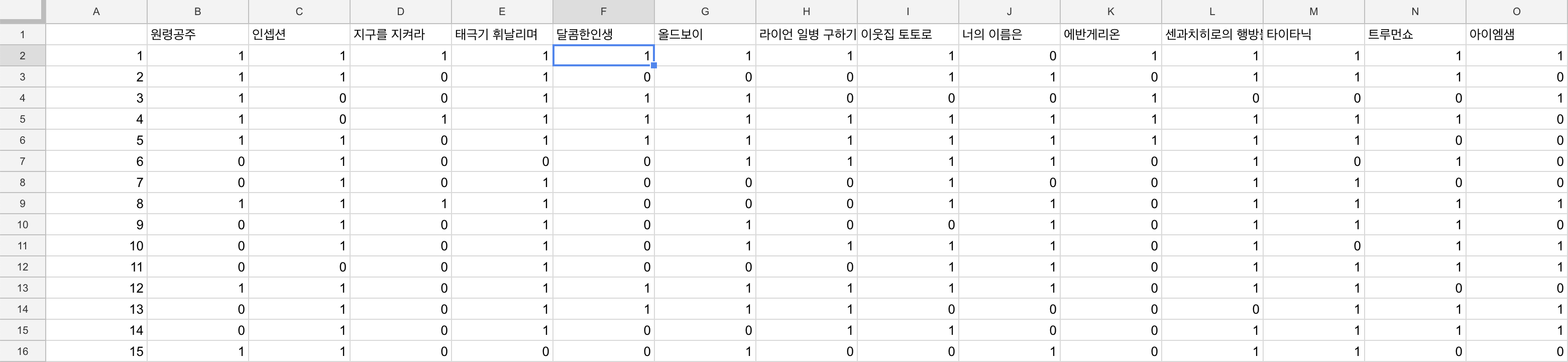
그런데 R에서 매트릭스에는 1번 열에 열번호를 이미 포함하고 있기 때문에 .csv파일에 1번열은 필요가 없어졌습니다. 그래서 1번열을 지워줍니다.
watch.movies.matrix<-watch.movies.matrix[,-1]
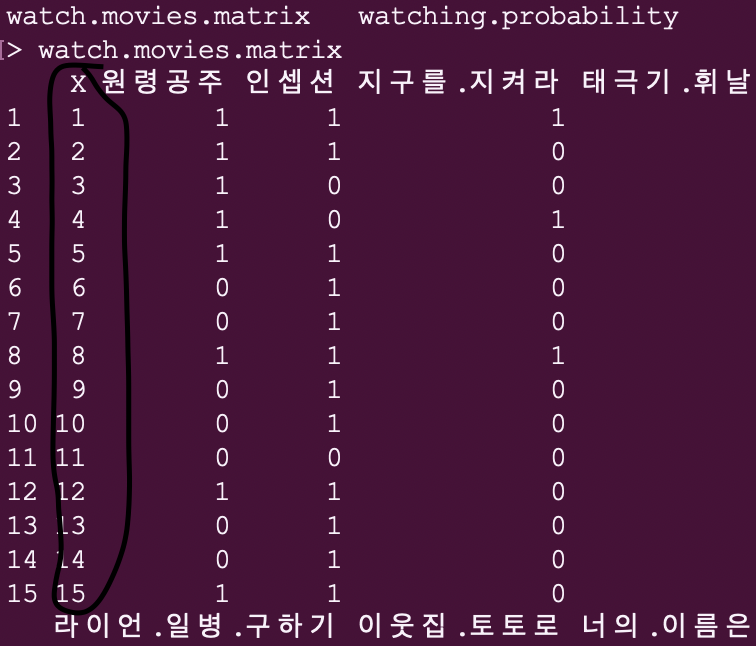
kNN 추천 시스템 만들기
상관계수 구하기
similarities<-cor(watch.movies.matrix)
열사이의 상관 계수를 구합니다.

원령공주와 원령공주는 똑같은 영화이기 떄문에 유사도가 1입니다. 원령공주와 인셉션은 조금이지만 서로 음의 관계라고 나옵니다.
거리구하기
그러나 kNN은 유사도가 아니라 거리를 이용하기 떄문에 유사도를 거리로 바꿉니다.
distances<- -log((similarities/2)+0.5)

추천하기
다음은 kNN함수를 사용하고 사용자에게 영화를 추천해 줍니다. 대신 이미 본영화인지 아닌지는 구분 하지 못합니다.
k.nearest.neighbors<-function(i, distances, k = 3){
return (order(distances[i,])[2:(k+1)])
}
watching.probability <- function(watcher, movie, watch.movies.matrix, distances, k = 3){
neighbors<-k.nearest.neighbors(movie, distances, k = k)
return(
mean(
sapply(
neighbors,
function(neighbor){
watch.movies.matrix[watcher, neighbor]
}
)
)
)
}
most.probable.movies<-function(watcher, watch.movies.matrix, distances, k = 3){
return (
order(
sapply(
1:ncol(watch.movies.matrix),
function(movie){
watching.probability(watcher, movie, watch.movies.matrix,distances, k = k)
}),
decreasing = TRUE
)
)
}
listing<-most.probable.movies(1, watch.movies.matrix, distances)
colnames(watch.movies.matrix)[listing[1:14]]


군집화 하기
ex.matrix<-as.matrix(watch.movies.matrix)
ex.mult <- ex.matrix %*% t(ex.matrix)
sqrt(sum((ex.mult[1,]-ex.mult[4,])^2))
ex.dist<-dist(ex.mult)
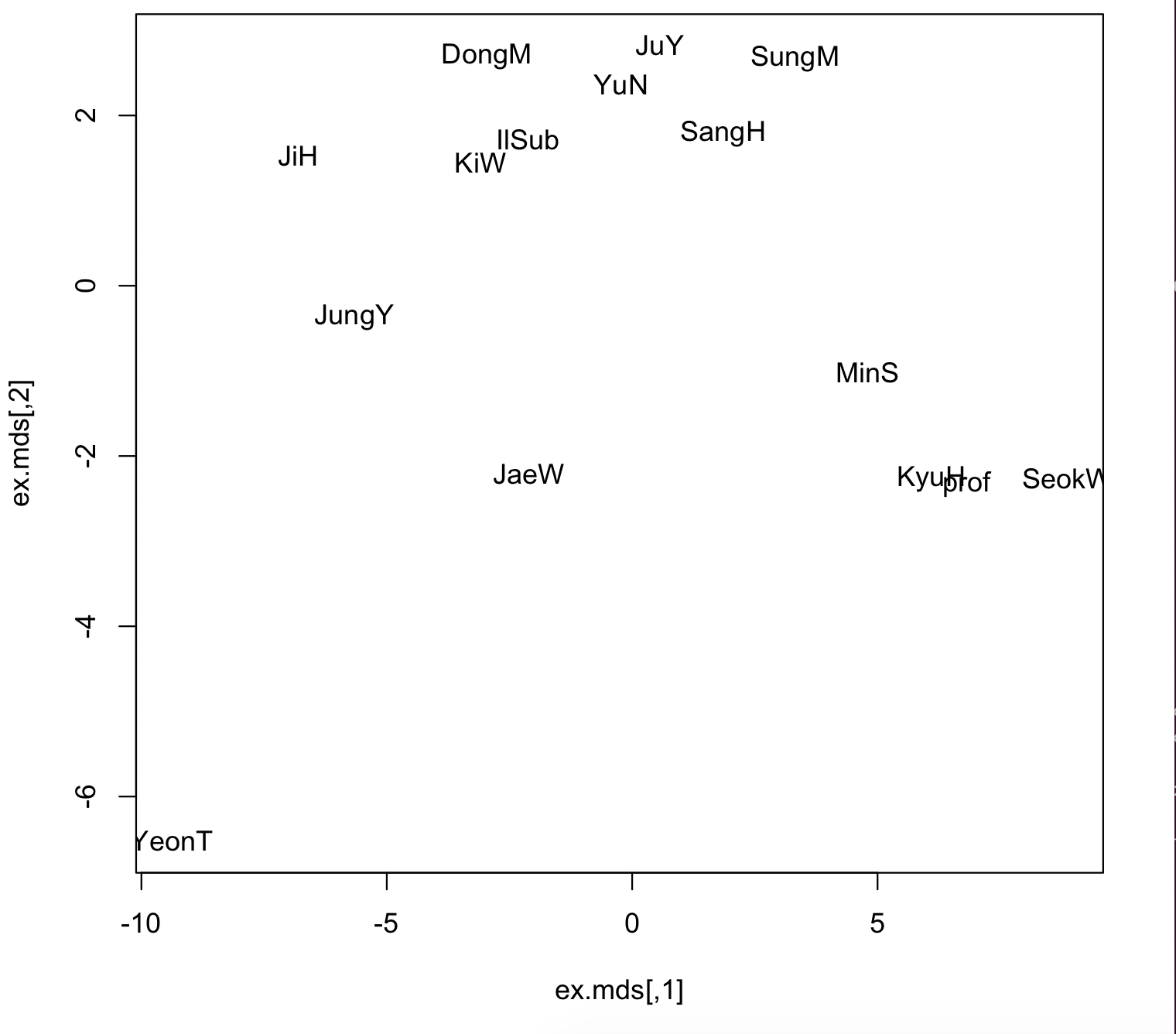
ex.mds<-cmdscale(ex.dist)
plot(ex.mds, type='n')
text(ex.mds, c('SeokW','JuY', 'YeonT', 'prof', 'KyuH', 'KiW', 'JiH', 'SungM', 'IlSub', 'SangH', 'DongM', 'MinS', 'JaeW', 'YuN', 'JungY'))