알고리즘의 기초
알고리즘의 특성
문제 풀이과정을 미리 만들어 놓은것이 알고리즘이다.
프로그램 개발 단계
-
정의 및 분석 단계
문제를 정확히 이해하고 구체적으로 정의한다.
-
입출력 설계 단계
입력과 출력으로 사용될 변수들의 종류와 타입을 결정하고 설계한다.
-
알고리즘 설계 단계
정의된 문제로부터 해답을 얻기 위한 과정을 정확하게 설계한다.
-
코딩 단계
하나의 프로그래밍 언어를 선택하여 구현한다.
-
테스트 단계
다양한 경우를 대상으로 프로그램의 정확성, 효율성등을 검사 한다.
알고리즘의 조건
-
입력
일반적으로 외부로부터 하나 이상의 입력을 받아들인다. 경우에 따라서 외부 입력이 없는 알고리즘이 가능하며 실행할 때마다 같은 결과를 산출한다.
-
출력
생성 결과물이 존재한다.
-
명확성
각 명령어는 모호하지 않고 분명해야 한다.
-
유효성
알고리즘을 구성하는 각 명령어는 컴퓨터에서 실행이 가능하여야 한다. 종이와 연필만 가지고도 시뮬레이션이 가능하여야 한다.
-
유한성
한번 시작하면 반드시 종료하여야 한다. 종료하더라도 실행시간의 유한성을 가져야 한다.
-
정확성
하나의 예외도 없이 모든 입력에 대해 항상 정확한 해답을 알려주어야 한다.
알고리즘의 표현
-
일상언어
모호한 표현으로 인해 의사소통에 어려움을 가져올 수 있으며 간결성에서 다른 표현 방법에 비해 큰 단점을 갖는다.
-
의사 코드
컴퓨터에서 실행이 가능한 코드는 아니지만 이와 유사한 모습을 지니는 코드를 일컫는다. 정형적인 문장과 제어 구조를 표현하면서 상세한 구현 레벨까지 신경을 쓰지 않아도 된다.
-
흐름도
알고리즘의 구조와 복잡성을 시각적으로 확인할 수 있지만 복잡한 알고리즘의 경우 상당한 공간이 필요하기 때문에 여러 페이지에 걸쳐 나타내어야 하는 문제도 있고 계층적 블록 구조나 중첩된 제어 구조를 표현하는데 한계가 있다.
-
프로그래밍 언어
상세한 구현 레벨까지 신경을 쓰다보면 핵심적인 알고리즘 구조에 집중하기 어려운 단점이 있다.
유클리드의 알고리즘 : 최대 공약수 구하기
현재 까지 알려진 가장 오래된 알고리즘. 양의 정수 m,n(m>n)이 주어졌을 때, m이 n으로 나누어 떨어지면 두 수의 최대 공약수는 n이고, m을 n으로 나눈 나머지가 r이면, m과 n의 최대공약수는 n과 r의 최대공약수와 같다는 사실을 전제로 하고 있다.
int gcd(int m, int n){
if(n == 0) return m;
return gcd(n, m % n);
}
알고리즘의 성능 평가
알고리즘은 시간과 공간으로 성능을 평가 받는다. 다만 하드웨어 기술의 발전으로 메모리 사용량보다는 실행시간이 더 중요하게 다루어지므로 일반적으로 실행 시간을 효율성의 첫 번째 기준으로 삼는다. 평가 정보는 각 알고리즘의 고유한 특성을 나타내는 유용한 정보다.
같은 문제 다른 성능
다항식의 계산
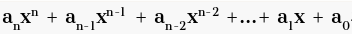
4X^4+6X^3+7X^2+3X+2
- 각 항별 계산
4*(X*X*X*X) + 6(X*X*X) + 7(X*X) + 3X + 2 곱셉 10회 덧셈 4회
- 호너의 규칙(Hornor’s rule)
(((4*X + 6)*X + 7)*X + 3)*X + 2 곱셉 4회 뎃셈 4회
| 차수 | 곱셈 횟수(각 항별 계산) | 덧셈 횟수 | 곱셈 횟수(호너의 규칙) | 덧셈 횟수 |
|---|---|---|---|---|
| 2 | 3 | 2 | 2 | 2 |
| 3 | 6 | 3 | 3 | 3 |
| 4 | 10 | 4 | 4 | 4 |
| 5 | 15 | 5 | 5 | 5 |
| 6 | 21 | 6 | 6 | 6 |
| 7 | 28 | 7 | 7 | 7 |
| 8 | 36 | 8 | 8 | 8 |
| 9 | 45 | 9 | 9 | 9 |
차수가 높아질 수록 곱셈 횟수에서 차이가 많이 난다.
1~n까지 정수 구하기
int sum1(int n)
{
int total = 0, i;
for(i = 1; i <= n;i++)
total += i;
return total;
}
int sum2(int n)
{
int total=0;
total = n*(1+n)/2;
return total;
}
sum1은 n이 커질수록 실행 시간이 오래 걸리게 되고 등차수열의 합공식을 이용한 알고리즘 sum2는 n의 값에 관계없이 일정한 실행 시간이 걸린다.
순차 탐색과 이진 탐색(최대값 찾기 알고리즘)
int sequential_search(int n, int List[], int num)
{
int i;
for(i = 0; i < n; i++)
if(List[i] == num) return i;
return -1;
}
만약 데이터가 정렬되어 있다면 더욱 효율적인 탐색이 가능하다.
int sequential_search(int n, int List[], int num)
{
int i;
for(i = 0; i < n; i++)
{
if(List[i] == num) return i;
if(List[i] > num) return -1; //원하는 값이 없다.
}
return -1;
}
순차탐색 도중에 찾고자하는 값보다 큰 값을 만나게 되면 배열에 그값이 존재하지 않음을 의미하므로 더 이상 진행할 필요가 없다.
int binary_search(int n, int List[], int num)
{
int low = 0, middle, high = n-1;
while(low <= high)
{
middle = (low + high)/2;
if(num == List[middle]) return middle;
else if(num < List[middle]) high = middle -1;
else low = middle +1;
}
return -1;
}
순차 탐색과 이진탐색의 비교 횟수
| 배열의 크기 | 순차 탐색(최대 비교 횟수) | 이진 탐색(최대 비교 횟수) |
|---|---|---|
| 1(2^0) | 1 | 1 |
| 512(2^9) | 512 | 10 |
| 524,288(2^19) | 524,288 | 20 |
| 536,870,912(2^29) | 536,870,912 | 30 |
| 549,755,813,888(2^39) | 549,755,813,888 | 40 |
| n(2^k) | n | log_2(n + 1) |
실행 시간 측정 vs 복잡도 분석
실행 시간 측정 방법은 단순하면서도 정확한 성능평가 방법이다.
실행 시간을 측정하는 예
# include<stdio.h>
# include<time.h>
void main(void)
{
clock_t start, stop;
double result;
start = clock();
//측정 하고자 하는 코드
stop=clock();
result=(double)(stop-start)/CLOCKS_PER_SEC;
printf("걸린 시간은 %f 초 입니다.", result);
}
그러나 실행 시간 측정은 몇가지 문제점들이 있다.
- 컴퓨터의 종류에 따라 처리 속도가 다르기 때문에 적어도 동일한 하드웨어를 사용하는 컴퓨터에서 실행 시간을 측정하여 비교하여야 한다.
- 같은 알고리즘도 실제 구현에 사용한 프로그래밍 언어의 종류와 컴파일러의 품질에 따라 실행 속도가 다를 수 있으며, 동일한 언어도 프로그래밍 스타일에 따라 측정 결과가 달라질 수 있다.
- 동일한 프로그램, 컴퓨터라도 실행 속도가 달라질 수 있다. UNIX같은 다중 사용자 시스템은 CPU를 다수의 사용자가 동시에 사용하므로, 같은 프로그램이라도 실행하는 시점에 시스템을 얼마나 많은 사용자가 사용하고 있느냐에 따라 실행 시간이 달라질 수 있다.
- 알고리즘의 실행 시간은 입력 데이터와 깊은 관계가 있지만 모든 가능한 입력 데이터에 대해 측정하는 것은 거의 불가능하다.
결국 실행 시간을 측정하는 방식에 대한 근본적인 해결책은 결국 측정하지 않고 알고리즘의 성능을 평가 하는 것이며 이를 알고리즘 복잡도 분석(algorith complexity analysis) 또는 알고리즘 분석(algorith analysis) 라고 한다.
복잡도 분석은 계산이나 추론 등을 통하여 알고리즘을 실행하는데 필요한 자원(공간, 시간)의 양을 결정하는 작업이다. 복잡도 분석의 결과는 시간복잡도 와 공간 복잡도 로 나타낸다.
연산(명령문)의 실행 횟수 를 이용해서 알고리즘 실행 시간을 대변한다.
시간 복잡도는 함수의 형태로 정의되며 T(n)이라 표기한다.
1부터 n까지 합 구하기 : 연산 횟수
int sum1(int n)
{
int total = 0, i; // 대입 1
for(i = 1; i <= n;i++) // 초기화 1, 비교 n+1, 증가 n
total += i; //복합 n
return total; //반환 1
} //T(n) = 3n + 4
int sum2(int n)
{
int total=0; //대입 1
total = n*(1+n)/2; //대입 1, 곱셈 1, 덧셈 1, 나눗셈 1
return total; // 반환 1
} // T(n) = 6
경우에 따라서는 기준 연산에 해당하는 연산만 고려하기도 한다.
int sum1(int n)
{
int total = 0, i; // 1
for(i = 1; i <= n;i++) // n+1
total += i; // n
return total; // 1
} //T(n) = 2n + 3
int sum2(int n)
{
int total=0; // 1
total = n*(1+n)/2; //1
return total; // 1
} // T(n) = 3
점근 분석과 점근 표기법
점근 분석(asymptotic analysis)은 실제 실행 횟수를 계산하여 함수화하는 복잡한 방법 대신 복잡도 함수의 추세를 표현함으로써 간단하지만 효과적으로 복잡도 분석을 가능하게 한다. 알고리즘의 절대적 성능대신 복잡도 함수의 점근적 증가율만을 나타낸다. 점근은 말그대로 “점점 근접시킴”을 뜻하며 입력의 크기를 점점 증가시켜 충분히 커지게 될 때 함수의 증가율을 분석 한다는 의미이다.
점근 분석에서 함수는 다항식의 항 가운데 차수가 가장 큰 항(들)만 선택해 계수를 1로 하여 사용한다.
다음은 점근 분석에서 자주 사용되는 함수들이며 아래로 내려갈수록 복잡도가 증가한다.
| 함수 | 이름 | 설명 |
|---|---|---|
| 1 | 상수형 | 입력의 크기와 관계없이 복잡도가 일정 |
| logn | 로그형 | 복잡도가 서서히 증가하며 로그함수의 밑은 대개 2가 생략 |
| n | 선형 | 입력의 크기에 비례적으로 복잡도가 증가 |
| nlogn | 선형 로그형 | 선형과 로크형이 결합된 형태 |
| n^2 | 2차형 | 입력의 제곱에 비례하여 복잡도 증가 |
| 2^n | 지수형 | 입력이 커짐에 따라 기하급수적으로 실행 시간이 증가 |
| n! | 팩토리형 | 입력이 커짐에 따라 기하급수적으로 실행 시간이 증가 |
점근 표기법
점근 복잡도(asymptotic complexity)는 점근 표기법(asymptotic)을 사용하여 나타낸다.
O 표기법
복잡도 함수 T(n)과 함수 g(n)에 대하여, 모든 n >= n0에 대하여 T(n) <= c * g(n)을 만족하는 2개의 양의 상수 c와 n0가 존재하면 T(n) = O(g(n))이다.
O(n)표기법을 사용하는 이유
- 복잡도의 정확한 증가율을 모르고 상한은 아는 경우이다.
예를 들어 어떤 알고리즘의 복잡도는 정확히 모르지만 점근적 증가율이 절대로 n^2을 넘지 않다는 것을 안다면 이 알고리즘의 점근 복잡도는 O(n^2)이라 이야기한다.
- 입력 데이터에 따라 증가율이 달라지는 경우이다.
- 관례적인 사용이다.
정확한 복잡도 증가율이 아니더라도 복잡도 증가율의 상한선이면 사람들이 관심을 갖는데 충분하다. “기껏해야”는 강한 호소력을 갖는 수식어이다.
주의할점
점근적 상한이라는 경계가 주는 불확실성 점근 복잡도 와 같은 실행 시간 증가율을 보일지 더 낮은 증가율을 보일지 알려 주지 않는다. 항상 빡빡한 상한을 사용하자.
T(n) = n^2 + O(n)은 O(n)에 속하는 함수 중 하나를 의미하는 표현이다.
Ω 표기법
복잡도 함수 T(n)과 함수 g(n)에 대하여, 모든 n>=n0에 대하여 T(n)>=c*g(n)을 만족하는 2개의 양의 상수 c와 n0가 존재하면 T(n)=Ω(g(n))이다.
Ω(n)을 사용하는 이유
- 복잡도 증가율의 하한을 아는 경우
- 입력 데이터에 따라 증가율이 달라지는 경우이다.
주의할점
점근적 상한과 비슷하다.
Θ 표기법
복잡도 함수 T(n)과 함수 g(n)에 대하여, 모든 n>=n0에 대하여 c1g(n)<=T(n)<=c2g(n)dmf 만족하는 3개의 양의 상수 c1, c2, n0가 존재 하면 T(n)=Θ(g(n)이다.
Θ표기법은 정확한 점근적 증가율을 사용한다. 즉 경계를 사용하지 않기 때문에 상한, 하한 표기법 보다 정밀하다.
점근 복잡도 쉽게 구하기
점근 복잡도 구하는 규칙
- 입력의 크기에 의존하는 순차적인 명령문(블록)은 각각의 점근 복잡도 함수를 더한다.
- 입력의 크기에 의존하는 중첩된 명령문(블록)은 각각의 점근 복잡도 함수를 곱한다.
- 호출되는 부프로그램은 해당 점근 복잡도 함수를 반영한다.
void sample(int n, int m)
{
for(i = 0; i < 10000; i++){...}//입력의 크기와 상관 없으므로 Θ(1)
func1(m); //복잡도가 Θ(m)이라 가정
...
for(i = 0; i < n; i++){...} //Θ(n)
for(i = 0; i < n; i++) //Θ(n^2)
for(j = 0; j < n; j++){...} //규칙2 중첩문은 곱한다.
...
for(i = 0; i < m; i++) //규칙2 중첩문은 곱한다.Θ(mn)
{
...
func2(n); //규칙3Θ(n)이라고 가정
...
}
} //계 Θ(n^2 + mn);
최악, 최선, 평균 복잡도
- 최악의 경우
- 최선의 경우
- 평균적인 경우
버블정렬이나 삽입정렬은 최선의 경우 Θ(n)이고 최악의 경우 Θ(n^2)인데 평균은 Θ(n^2)이며 퀵정렬은 최선의 경우 Θ(nlogn)이고 최악의 경우 Θ(n^2)인데 평균적인 경우 Θ(nlogn)이다.
최악의 경우는 여럿 있을 수도 있지만 최악의 경우 시간 복잡도는 유일하다. 최선의 경우도 여럿 있을 수 있지만 최선의 경우 시간 복잡도는 유일하다. 평균적인 경우 시간 복잡도 역시 유일하다 따라서 세 가지 경우의 점근 복잡도는 Θ표기법으로 나타내는 것이 원칙이다.